Apache Spark is an open source, distributed computing system designed for fast and general-purpose big data processing. Spark has become one of the most popular big data frameworks in the industry due to its speed, ease of use, and ability to handle complex data analytics workflows across large-scale datasets.
At its core, Apache Spark supports a wide range of workloads including batch processing, real-time stream processing, machine learning, graph analytics, and SQL queries.
The Apache Spark architecture is based on a master-slave model consisting of a Driver and multiple Executors. The Driver is responsible for orchestrating the execution of tasks, while Executors perform the actual computation on worker nodes. Spark uses Resilient Distributed Datasets (RDDs) and DataFrames to efficiently process and store data in memory, which significantly improves performance over traditional disk-based processing frameworks like Hadoop MapReduce.
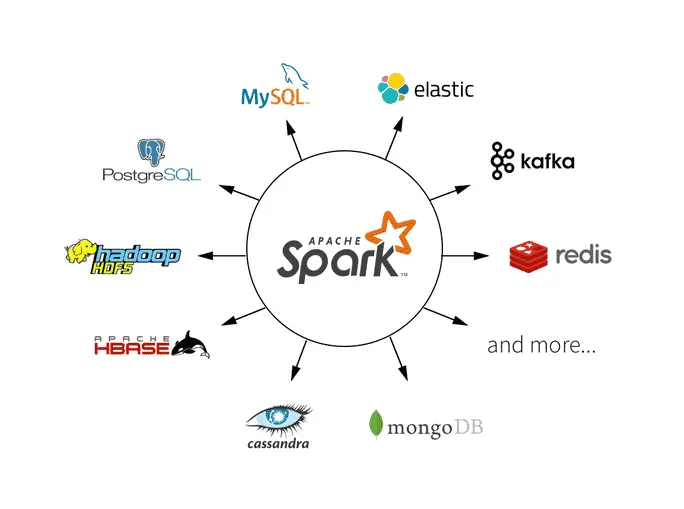
In modern cloud environments, Spark as a Service has emerged as a convenient model for deploying and running Spark applications without managing the underlying infrastructure. Cloud providers offer fully managed Spark services that allow users to focus on data processing and analytics rather than operational complexities. This approach supports elastic scaling, job scheduling, and seamless integration with cloud storage and other analytics tools.